
Avoiding reinventing the wheel - use MULTISET EXCEPT to get set relative complement
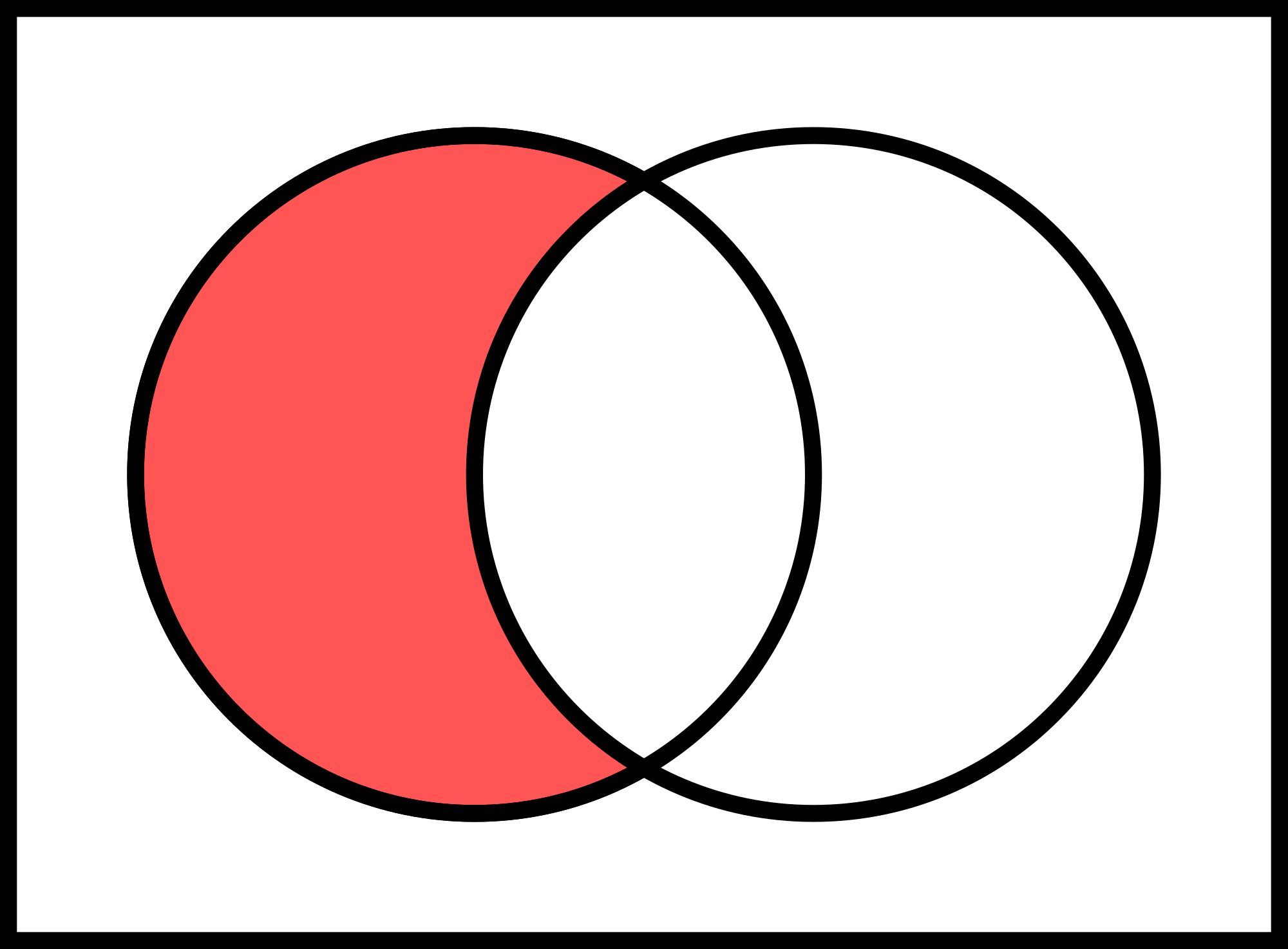
The trouble is, that this functionality already natively exists in PL/SQL (and SQL) - the developer had actually reinvented the wheel. In set theory this is called a relative complement and PL/SQL and SQL has operator MULTISET EXCEPT to perform this set operation.
So just as a warning to all that you should really be aware of the built-in functionality of any programming language, I'll show you this function and how I replaced it.
First I create the nested table type along with a procedure that simply dumps the content of that type to the server output.
create or replace type num_tab_type as table of number
/
create or replace procedure dump_num_tab( p_nt num_tab_type )
is
begin
if p_nt is null then
dbms_output.put_line('NULL');
else
dbms_output.put_line('Count: '||p_nt.count);
for i in 1..p_nt.count loop
dbms_output.put_line(lpad(i,5)||': '||p_nt(i));
end loop;
end if;
end dump_num_tab;
/
Then I have the function as I found it (renamed identifiers and reformatted for this demo, but functionality exactly as I found it.) The code loops through the elements of the two nested tables comparing elements individually to each other - lots of work.
create or replace function num_tab_complement ( p_nt_1 num_tab_type, p_nt_2 num_tab_type)
return num_tab_type
is
v_retval num_tab_type;
v_retcnt number := 0;
v_present boolean;
begin
v_retval := num_tab_type();
if p_nt_1 is not null then
for i in 1..p_nt_1.count loop
v_present := false;
if p_nt_2 is not null then
for j in 1..p_nt_2.count loop
if p_nt_1(i) = p_nt_2(j) then
v_present := true;
exit;
end if;
end loop;
end if;
if not v_present then
v_retval.extend(1);
v_retcnt := v_retcnt + 1;
v_retval(v_retcnt) := p_nt_1(i);
end if;
end loop;
end if;
return v_retval;
end num_tab_complement;
/
Testing the function with some various cases of two different nested tables.
declare
nt1 num_tab_type;
nt2 num_tab_type;
nt3 num_tab_type;
begin
dbms_output.put_line('-- case 1 --');
nt1 := num_tab_type(1,2,3);
nt2 := num_tab_type(2,4);
nt3 := num_tab_complement(nt1, nt2);
dump_num_tab(nt3);
dbms_output.put_line('-- case 2 --');
nt1 := num_tab_type(1,2,3);
nt2 := num_tab_type(4,3,2,1);
nt3 := num_tab_complement(nt1, nt2);
dump_num_tab(nt3);
dbms_output.put_line('-- case 3 --');
nt1 := num_tab_type(1,2,3);
nt2 := num_tab_type();
nt3 := num_tab_complement(nt1, nt2);
dump_num_tab(nt3);
dbms_output.put_line('-- case 4 --');
nt1 := num_tab_type(1,2,3);
nt2 := NULL;
nt3 := num_tab_complement(nt1, nt2);
dump_num_tab(nt3);
dbms_output.put_line('-- case 5 --');
nt1 := num_tab_type();
nt2 := num_tab_type(2,4);
nt3 := num_tab_complement(nt1, nt2);
dump_num_tab(nt3);
dbms_output.put_line('-- case 6 --');
nt1 := NULL;
nt2 := num_tab_type(2,4);
nt3 := num_tab_complement(nt1, nt2);
dump_num_tab(nt3);
end;
/
The implementation chosen by the original developer was to treat NULL valued nested tables as if they were empty nested tables, as can be seen in the output. This is not standard, but the application presumably expects the code to work this way.
-- case 1 --
Count: 2
1: 1
2: 3
-- case 2 --
Count: 0
-- case 3 --
Count: 3
1: 1
2: 2
3: 3
-- case 4 --
Count: 3
1: 1
2: 2
3: 3
-- case 5 --
Count: 0
-- case 6 --
Count: 0
So now I turn to the built-in functionality MULTISET EXCEPT for getting a relative complement of two sets.
I could in principle avoid the function completely and just use MULTISET EXCEPT those places where the function is called. This would normally be my preference.
Except that in this case the original function did a non-standard handling of NULL values, so to make certain the application does not break, I'll just replace the inner workings of the function with a little CASE structure to handle the NULL special cases and otherwise just return the MULTISET EXCEPT of the two sets.
create or replace function num_tab_complement ( p_nt_1 num_tab_type, p_nt_2 num_tab_type)
return num_tab_type
is
begin
return
case
when p_nt_1 is null then
num_tab_type()
when p_nt_2 is null then
p_nt_1
else
p_nt_1 multiset except all p_nt_2
end;
end num_tab_complement;
/
And testing the new function with the exact same test anonymous block gives the same output, so the replacement will not break the application, just make it faster.
-- case 1 --
Count: 2
1: 1
2: 3
-- case 2 --
Count: 0
-- case 3 --
Count: 3
1: 1
2: 2
3: 3
-- case 4 --
Count: 3
1: 1
2: 2
3: 3
-- case 5 --
Count: 0
-- case 6 --
Count: 0
A couple of notes:
- I used MULTISET EXCEPT ALL (ALL is the default, the alternative is DISTINCT.) This does not entirely match the original function. In the original, if there are duplicates of a value in p_nt_1, either that value will be in the output nested table the same number of occurrences as in p_nt_1 (if the value does not exist in p_nt_2) or that value will not be in the output nested table at all (if the value exists minimum once in p_nt_2.) So here the replacement function does not entirely emulate the original, and I can only do this because I know there will never be duplicates in the nested tables in this application. If there had been duplicates, I would question whether the original function was a correct implementation and find out whether ALL or DISTINCT would be the correct replacement.
- Using the MULTISET instead of the Do-It-Yourself code has many advantages like for example speed. But a very important advantage is that I do not have to care about whether the nested tables are dense or sparse. Of course I could have rewritten the original DIY code to handle sparse nested tables, but it is just so much easier when I don't have to worry about that at all and just let the database figure it out.
Moral: Be lazy. Use the built-in functionality. It is only in very rare very special cases that it just might be possible for you to DIY something better and faster than what the database can do natively ;-)
The code shown can be tried out on LiveSQL here: https://livesql.oracle.com/apex/livesql/s/fmmlw2stbi30fcbzf5pg3ud0n
Comments
Post a Comment